Data Privacy in AI Systems: What Teams Need to Know

Summary
AI systems rely heavily on personal data, creating complex privacy, regulatory, and security challenges. With evolving global laws like GDPR and the EU AI Act, teams must adopt privacy-by-design, minimize data use, and implement governance frameworks. Beyond compliance, strong privacy practices enhance trust, reduce risk, and create competitive advantage in AI-driven markets.
Key insights:
Privacy by Design חובה: Data protection must be integrated into AI systems from the start, not added later.
Expanding Regulations: Global frameworks like GDPR and EU AI Act impose strict, overlapping compliance obligations.
AI-Specific Risks: Issues like data leakage, memorization, and prompt injection require new safeguards.
Operational Discipline: Privacy requires continuous processes like DPIAs, audit trails, and governance.
PETs Adoption: Technologies like differential privacy and federated learning reduce data exposure risks.
Trust as Advantage: Strong privacy practices directly impact customer trust and business competitiveness.
Introduction
Artificial intelligence is no longer an emerging technology; it is an operating reality. Yet embedded in its rapid adoption is a largely unresolved tension: AI systems are data-hungry by design, processing personal information at scale, in real time, and often retaining it well beyond what conventional software would require.
That tension has become regulatory, reputational, and increasingly litigious. With over 1,000 AI-related laws proposed globally in 2025 alone, this is one of the fastest-evolving compliance domains in modern business, and for product and engineering teams, the implication is clear: privacy must be architected from the beginning, not addressed as a downstream legal review. This insight provides the conceptual grounding, regulatory context, and operational guidance necessary to build AI systems that are not only capable but also trustworthy.
Key Concepts and Definitions
Before examining the regulatory and operational landscape, it is important to establish a shared conceptual vocabulary. The following definitions underpin this analysis.
1. Personal Data
Any information that relates to an identified or identifiable natural person. In the context of AI, this includes not only obvious identifiers such as names and national ID numbers, but also indirect identifiers; IP addresses, behavioral profiles, biometric patterns, and inferences drawn from aggregated data. The GDPR's definition is deliberately broad, and many AI systems process personal data without their operators fully recognizing it as such.
2. Data Privacy
Data privacy involves the proper handling of personal information, ensuring it is protected from unauthorized access. In the context of artificial intelligence (AI), data privacy raises significant ethical concerns and requires adherence to best practices. Given the propensity of AI systems to process vast amounts of personal data, it is imperative to implement robust privacy safeguards.
3. Privacy by Design (PbD)
A framework originating from the GDPR (Article 25) that mandates the embedding of data protection into the design and architecture of systems, not as an afterthought, but as a foundational principle. For AI, this means conducting privacy risk assessments during system design, applying data minimization at the point of collection, and building in user rights (access, deletion, portability) as native capabilities rather than operational overrides.
4. Data Minimization
The principle that only the minimum amount of personal data necessary for a specified purpose should be collected and processed. In AI systems, this principle is frequently violated at the training data stage, where larger datasets are assumed to produce better models, an assumption that must be balanced against the legal obligation to process only what is necessary and proportionate.
5. AI Model Anonymization
The process by which personal data is processed in such a way that individuals can no longer be identified. The European Data Protection Board's Opinion 28/2024 confirmed that AI models trained on personal data must, in most cases, be considered subject to the GDPR, meaning that true anonymization must be verified through formal re-identification attack testing rather than merely assumed.
6. Privacy-Enhancing Technologies (PETs)
A class of technical tools, including differential privacy, federated learning, pseudonymization, tokenization, and homomorphic encryption, that enable data processing while reducing exposure of personal information. PETs are increasingly recognized by regulators as concrete implementation mechanisms for Privacy by Design obligations.
7. Data Processing Agreement (DPA)
A legally binding contract between a data controller (the enterprise deploying AI) and a data processor (typically a third-party AI platform or vendor). The DPA defines the scope of authorized processing, security obligations, and breach notification requirements. Under GDPR Article 28, these agreements are mandatory for any enterprise-to-vendor AI deployment.
The Regulatory Landscape
The regulatory environment for AI and data privacy has fundamentally transformed over the past three years. What was once a fragmented collection of sector-specific rules has become an overlapping architecture of comprehensive legal frameworks that directly shape how AI systems are designed, trained, and deployed.
1. The EU AI Act and GDPR: A Dual Compliance Reality
The European Union has established the world's most comprehensive AI governance framework through two converging regulations. The GDPR, in force since 2018, governs personal data processing and applies to any AI system touching EU residents' data, regardless of where it is built. The EU AI Act, adopted in 2024, adds a risk-based classification layer on top: systems are tiered as unacceptable risk (prohibited), high risk (bias detection, human oversight, and data quality obligations), limited risk (transparency only), or minimal risk (no specific burden). For most enterprise teams, the critical question is not whether their system is regulated, but at which tier.
Critically, both frameworks apply simultaneously wherever personal data is used in AI development. France's CNIL has confirmed this dual obligation explicitly, noting that an AI system based on personal data must be developed with a well-defined, explicit, and legitimate objective under both regimes.
2. United States: A Patchwork Evolving Toward Coherence
The United States has taken a markedly different approach, relying on a combination of sector-specific federal law, state-level privacy statutes, and regulatory agency enforcement rather than comprehensive federal legislation. As of early 2025, 20 U.S. states have enacted privacy laws, and California enacted the first AI-specific transparency law in the country through the Transparency in Frontier Artificial Intelligence Act (TFAIA). The Federal Trade Commission has taken an increasingly active stance, penalizing companies for using unconsented data in AI model training, signaling that enforcement is accelerating even without federal legislation.
For enterprise teams operating across U.S. jurisdictions, the practical challenge is a compliance matrix that varies by state, sector, and data type. States like California and Colorado now mandate universal opt-out mechanisms for data sharing, requirements that directly affect AI training pipelines and model personalization capabilities.
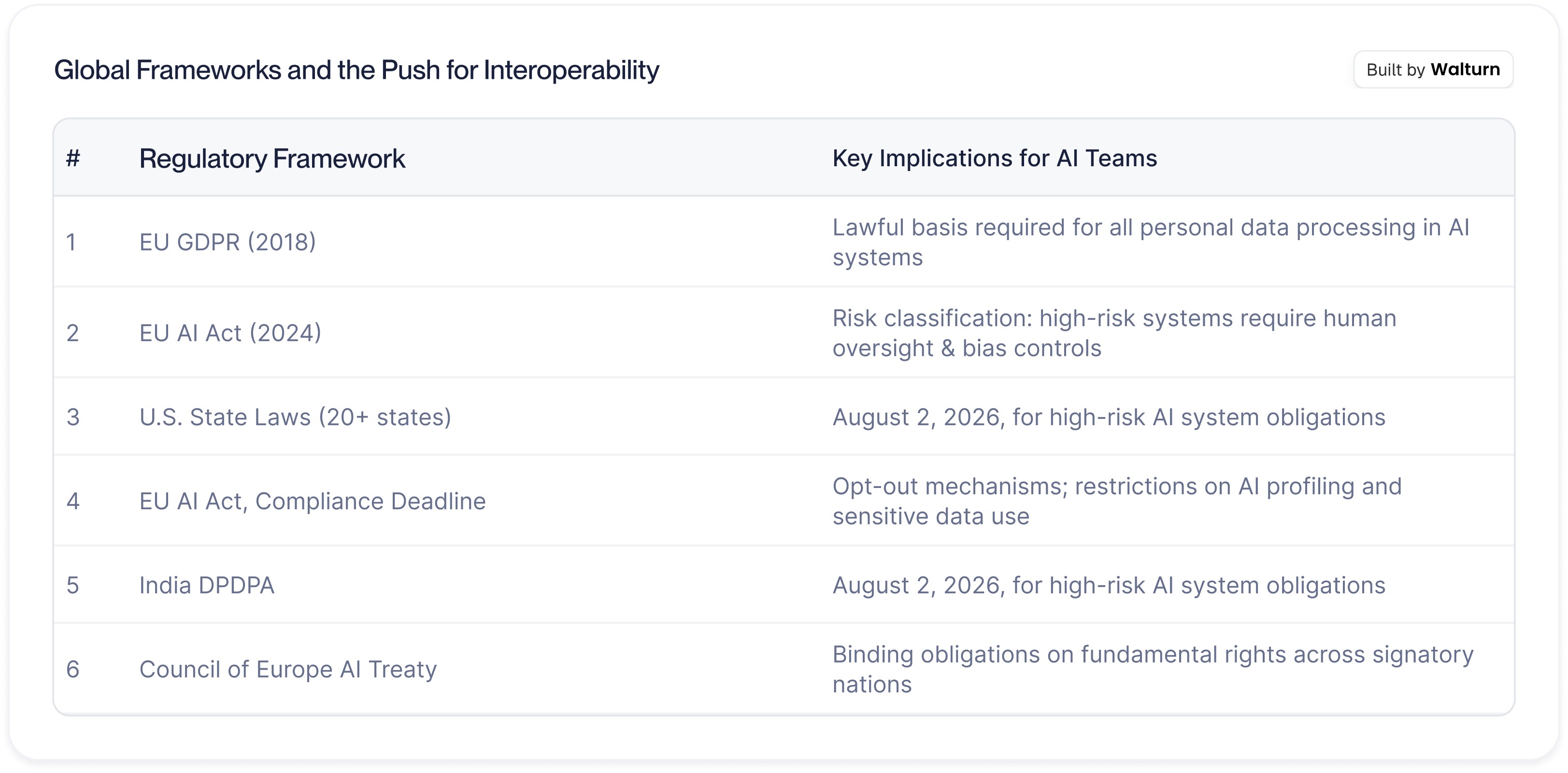
3. Global Frameworks and the Push for Interoperability
Beyond the EU and the U.S., data privacy regulation for AI is advancing across major economies. India's Digital Personal Data Protection Act (DPDPA) imposes robust consent requirements and significant penalties. China's Personal Information Protection Law (PIPL) mandates data localization and transparency in algorithmic decision-making. The Council of Europe's Framework Convention on Artificial Intelligence, the world's first legally binding international AI treaty, opened for signature in September 2024 and establishes obligations applicable to both public and private actors.
For multi-jurisdictional enterprises, the most defensible strategy is to align internal AI systems with the most stringent applicable standard, typically EU norms, while implementing jurisdiction-specific controls as overlays. This approach reduces the operational overhead of managing divergent compliance requirements while providing a robust baseline that satisfies the majority of regulatory demands.
Privacy Risks Specific to AI Systems
AI systems introduce a qualitatively different category of privacy risk compared to traditional software. The following represent the most operationally significant threats that enterprise teams must design against.
1. Training Data Memorization
Machine learning models can memorize specific data points from their training sets, and can be induced to reproduce them through carefully constructed prompts. Academic research has demonstrated that large language models and other deep learning architectures can, in certain conditions, disclose fragments of training data verbatim. The EDPB's Opinion 28/2024 addressed this directly, confirming that models trained on personal data must generally be treated as subject to GDPR, and that anonymization cannot be presumed without formal re-identification testing.
2. Data Leakage Across Sessions
In multi-user AI deployments, including enterprise chatbots, customer service agents, and AI-assisted platforms, there is a meaningful risk that data from one user's session surfaces in another's. This is not a hypothetical edge case: it represents one of the most commonly observed vulnerabilities in production AI agent architectures. Proper session isolation, data scoping controls, and output filtering are technical prerequisites, not optional enhancements.
3. Shadow AI and Unsanctioned Tools
Research in 2025 found that approximately 15% of employees regularly paste sensitive information, including personally identifiable information, financial data, and internal business records, into public large language models without procurement or data protection review. These "shadow AI" deployments create data exposure that is difficult to audit, impossible to remediate after the fact, and potentially in direct violation of enterprise data handling obligations.
4. Prompt Injection
Prompt injection attacks involve embedding malicious instructions within data inputs that manipulate an AI model's behavior, including inducing it to reveal internal context, tool outputs, or session history. Unlike traditional injection vulnerabilities, prompt injection cannot be solved purely at the input sanitization layer. It requires architectural separation of trusted and untrusted data flows throughout the AI system.
5. Retrieval-Augmented Generation (RAG) Without Redaction
Organizations deploying RAG architectures, where AI systems retrieve and synthesize information from document repositories, face a specific risk: if those repositories contain unredacted personal data, a retrieval query can surface it in AI-generated outputs. Privacy controls must be applied at the data ingestion layer, not only at the point of model inference.
An Operational Framework for AI Data Privacy
Compliance with data privacy requirements in AI systems is not a single event; it is a continuous operational discipline. The following framework, grounded in established regulatory guidance and industry practice, provides teams with the structural foundation for privacy-respecting AI development.
1. Establish Lawful Basis Before Deployment
Every AI system that processes personal data must have a clearly documented legal basis before it goes into production. Under GDPR, the available bases include consent, legitimate interest, contractual necessity, and legal obligation. The choice of legal basis is consequential: it shapes the rights individuals hold over their data and the documentation obligations the organization must maintain. Legitimate interest, often the most operationally convenient basis, requires a formal three-step balancing assessment demonstrating that the organization's interest is proportionate and does not unduly infringe on data subjects' rights.
2. Apply Data Minimization at the Architecture Level
The instinct in AI development is to collect as much data as possible on the premise that more data yields better models. Privacy law inverts this incentive: collect only what is necessary for the defined purpose, and retain it only for as long as that purpose requires. This means defining the AI system's purpose with specificity before data collection begins, scoping training datasets to that purpose, and building automated retention and deletion policies into the data pipeline, not as bolt-on features, but as native architecture.
3. Conduct Privacy Impact Assessments (PIAs)
For AI systems involving high-risk processing, including large-scale processing of personal data, automated decision-making with legal or similarly significant effects, or systematic monitoring, a formal Data Protection Impact Assessment (DPIA) is mandatory under GDPR. Beyond the regulatory obligation, DPIAs are operationally valuable: they force cross-functional alignment between engineering, legal, and product teams on data flows, risk tolerance, and mitigation measures before deployment, rather than after an incident.
4. Build Cross-Functional Governance
Privacy in AI cannot be owned by any single function. Effective governance requires genuine collaboration between engineering (who build the systems), legal (who interpret the obligations), product (who define the use cases), and security (who manage the threat surface). Organizations that treat privacy as a legal overhead to be managed at the end of the development cycle consistently underperform on both compliance and incident resilience. Those that integrate privacy review into sprint planning, design reviews, and deployment gates build durable organizational capability.
5. Deploy Privacy-Enhancing Technologies
PETs translate Privacy by Design principles into technical controls. Differential privacy adds calibrated noise to training data to prevent re-identification. Federated learning enables model training without centralizing raw personal data. Tokenization and pseudonymization reduce identifiability at the data pipeline level. At the inference layer, pre-prompt redaction and PII masking prevent personal data from reaching the model unnecessarily. Organizations investing in PETs are increasingly viewed by regulators as demonstrating proactive good faith, a posture that materially affects enforcement outcomes.
6. Maintain Audit Trails and Documentation
Regulatory accountability under both the GDPR and the EU AI Act is not merely about having the right policies in place; it is about being able to demonstrate their implementation. This requires maintaining records of processing activities (RoPAs), logging data access and transformations through the AI pipeline, documenting the outcomes of DPIAs and legitimate interest assessments, and retaining evidence of consent collection and withdrawal. For high-risk AI systems, this documentation infrastructure is a compliance prerequisite. For all AI systems, it is the foundation of incident response capability.
Business Implications: Privacy as Competitive Positioning
The conventional framing of data privacy as a compliance cost is strategically inadequate for 2025 and beyond. Research consistently demonstrates that consumer trust, increasingly contingent on perceived data stewardship, is a material business asset.
Pew Research Center found that 81% of Americans believe the risks of corporate data collection outweigh the benefits, and 70% of adults report they do not trust companies with AI-generated data handling. Security Magazine (2024) reported that 66% of consumers would not trust a company following a data breach, with 75% stating they would sever ties with a brand after any cybersecurity incident. In B2B markets, privacy certification and compliance track records have become procurement criteria: enterprise buyers are evaluating vendors on the strength of their data protection architecture, not merely their feature sets.
The cost calculus also favors investment. For enterprises deploying AI in European markets, GDPR sanctions can reach 4% of global annual revenue. A single mid-sized enterprise data breach involving an AI chatbot resulted in a £1.5 million enforcement action in 2024. Meanwhile, the investment required to implement privacy-by-design architecture for a typical enterprise AI deployment is a fraction of the regulatory exposure it eliminates.
Conclusion
Data privacy in AI systems is no longer a niche legal concern; it is a cross-functional discipline that touches every team involved in building, deploying, or managing AI. The regulatory architecture governing it is expanding across jurisdictions and enforcement intensity, the technical risks are real, and the business case for proactive investment is unambiguous.
The imperative for teams is clear: establish lawful bases, minimize data collection, implement privacy-by-design, and maintain documentation that demonstrates accountability. These are not aspirational standards; they are the operational baseline for AI systems that will withstand scrutiny, earn trust, and scale responsibly. Organizations that build this foundation today will not merely be compliant; they will be better positioned to move faster and operate with confidence in an increasingly regulated market.
Authors




Build Privacy-First AI Systems
Walturn helps teams design AI architectures with privacy, compliance, and scalability built in from day one











































